My name is Jing Conan Wang, a co-founder and CTO of Storytell.ai. In October 2022, together with two amazing partners DROdio and Erika, we founded Storytell.ai, dedicated to distilling signal from noise to improve the efficiency of knowledge workers. The reason we chose the name Storytell.ai is that storytelling is the oldest tool for knowledge distillation in human history. In ancient times, people sat around bright campfires telling stories, allowing human experiences and wisdom to be passed down through generations.
The past year has been an explosive one for large language models (LLMs). With the meteoric rise of ChatGPT, LLMs have quickly become known to the general public. I hope to share my own personal story to give people a glimpse into the grandeur of entrepreneurship in the field of large language models.
From Google and Beyond
Although ChatGPT comes from OpenAI, the roots of LLMs lie in Google Brain – a deep learning lab founded by Jeff Dean, Andrew Ng, and others. It was during my time at Google Brain that I formed a connection with LLMs. I worked at Google for five years, spending the first three in Ads engineering and the latter two in Google Brain. Not long after joining Google Brain, I noticed that one colleague after another began shifting their focus to research on large language models. That period (2017-2019) was the germination phase for LLMs, with a plethora of new technologies emerging in Google’s labs. Being in the midst of this environment allowed me to gain a profound understanding of the capabilities of LLMs. Particularly, there were a few experiences that made me realize that a true technological revolution in language models was on the horizon:
One was about BERT — one of the best LLMs before ChatGPT: One day in 2017, while I was in a Google Cafe, a thunderous applause broke out. It turned out that a group nearby was discussing the results of an experiment. Google provides free lunches for its employees, and lunchtime often brings people together to talk about work. A colleague mentioned to me: “Do you know about BERT?” At the time, I only knew BERT as a character from the American animated show Sesame Street, which I had never watched. My colleague told me: “BERT has increased Google Search revenue by 1% in internal experiments.” Google’s revenue was already over a hundred billion dollars a year, meaning this was equivalent to several billion dollars in annual revenue. This was quite shocking to me.
Another was my experience with Duplex: Sunder Pichai released a demo of an AI making phone calls at Google I/O 2018, which caused a sensation in the industry. The project, internally known as Duplex, was something our group was responsible for in terms of related model work. The demo only showed a small part of what was possible; internally, there was a lot more data on similar AI phone calls. We often needed to review the results of the Duplex model. The outcome was astonishing; I could hardly differentiate between conversations held by AI or humans.
Another gain was my reflection on business models. Although I had worked in Google’s commercialization team for a long time and the models I personally worked on generated over two hundred million dollars in annual revenue for Google, I realized that an advertising-driven business model would become a shackle for large language models. The biggest problem with the advertising business model is that it treats users’ attention (time) as a commodity for sale. To users, it seems like they are using the product for free, but in reality, they are giving their attention to the platform. The platform has no incentive to increase user efficiency but rather to capture more attention to sell at a very low price. Valuable users will eventually leave the platform, leading to the platform itself becoming increasingly worthless.
One of the AI applications I worked on at Google Brain was the video recommendation on YouTube’s homepage. The entire business model of Google and YouTube is based on advertising; longer user watch time means more ad revenue. Therefore, for applications like YouTube, the most important goal is to increase the total time users spend on the app. At that time, TikTok had not yet risen, and YouTube was unrivaled in the video domain in the United States. In YouTube’s model review meetings, we often joked that the only way for us to get more usage is to reduce the time people spend eating and sleeping. Although I wanted to improve user experience through better algorithms, no matter how I adjusted, the ultimate goal was still inseparable from increasing user watch time to boost ad revenue.
During my contemplation, I gradually encountered the Software as a Service (SaaS) business model and felt that this was the right model for large-scale models. In SaaS, users only pay for subscriptions if they receive continuous value. SaaS is customer-driven, whereas Google’s culture overly emphasizes an engineering culture and neglects customer value, making it very difficult to explore this path within Google. Ultimately, I was determined to leave Google and decided to start my own SaaS company. At the end of 2019, I joined a SaaS startup as a Founding Member and learned about the building process of a SaaS company from zero to one.
At the same time, I was also looking for good partners. Finally, in 2021 I was able to meet two amazing partners DROdio and Erika and we started storytell.ai in 2022.
Build a company of belonging
The first thing we did at the inception of our company was to clarify our vision and culture. We want to build a company of belonging by defining our vision and culture clearly. The vision and culture of a company truly define its DNA; the vision helps us know where to go, and the culture ensures we work together effectively.
Storytell’s vision is to become the Clarity Layer, using AI to help people distill signal from noise (https://go.storytell.ai/vision). — a company with great vision and culture.
We have six cultural values: 1) Apply High-Leverage Thinking. 2) Everyone is Crew. 3) Market Signal is our North Star. 4) We Default to Transparency. 5) We Prioritize Courageous Candor in our Interactions. 6) We are a Learning Organization. Please refer to this https://go.Storytell.ai/values for details.
We also pay special attention to team culture building during the company’s creation process. From the start, we hope to work hard but also play harder. We have offsite gatherings every quarter. The entire team is very fond of outdoor activities and camping, so we often hold various outdoor events (we have a shared album with photos from the very first day of our establishment). We call ourselves the Storytell Crew, hoping that we can traverse the stars and oceans together like an astronaut crew.
Build a Product that people love
In the early stages of a startup, finding Product-Market Fit (PMF) is of utmost importance. Traditional SaaS software emphasizes specialization and segmentation, with typically only a few companies iterating within each niche, and product stability may take years to achieve. This year, ChatGPT brought about a radical market change. The explosive popularity of ChatGPT is a double-edged sword for SaaS software entrepreneurs. On one hand, it reduces the cost of educating the market; on the other hand, the entire field becomes more competitive, with a surge of entrepreneurs entering the market and diverting customer resources. The influx of ineffective traffic brought by ChatGPT ultimately fails to convert effectively into the product.
Many believe that the moat for startups applying large models is technology or data. We think neither is the case. The real moat is the skill in wielding this double-edged sword. Good swordsmanship can transform both edges of the sword into a force that breaks through barriers:
- On one hand, for traditional SaaS, it’s about leveraging the momentum of ChatGPT to maximize the impact on traditional SaaS. Make customers feel the urgency to keep up with the times. Develop AI Native features that incumbents find hard to follow.
- On the other hand, use the competition to bring about a thriving ecosystem and have a methodical and steadfast approach in product iteration, ultimately shortening the product iteration cycle to achieve the greatest momentum.
We follow these two principles in our own product iteration.
1) Data-guided: In the iteration process, we use the North Star Metric to guide our general direction. Our North Star Metric is:
Effective Reach = Total Reach x Effective Ratio
Total reach is the number of summaries and questions asked on our platform each day. The Effective Ratio is a number from 0 to 1 that indicates how much of the content we generate is useful for users.
2) User-driven. Drive product feature adjustments through in-depth communication with users. For collecting user feedback, we’ve adopted a combination of online and offline methods. Online, we use user behavior analysis tools to identify meaningful user actions and follow up with user interviews to collect specific feedback. Offline, we organize many events to bring users together for brainstorming sessions.
With this approach in mind, our product has undergone multiple rounds of iteration in the past year.
V0: Slack Plugin
Since June 2022, Erika, DROdio and I have been conducting numerous customer discovery calls. During our interviews with users, we often needed to record the conversations. We primarily used Zoom, but Zoom itself did not provide a summarization tool back then. I used the GPT-3 API to create a Slack plugin that automatically generates summaries. Whenever we had a Zoom meeting, it would automatically send the meeting video link to a specific Slack channel. Subsequently, our plugin would reply with an auto-generated summary. Users could also ask some follow-up questions in response.
At that time, there weren’t many tools available for automatically generating summaries, and every user we interviewed was amazed by this tool. This made us gradually shift our focus towards the direction of automatic summarization. The Slack plugin allowed us to collect a lot of user feedback. By the end of December 2022, we realized the limitations of the Slack plugin.
- Firstly: Slack is a system with high friction. Only system administrators can install plugins; regular employees cannot install plugins themselves.
- We had almost no usage of our Slack plugin over the weekends. The likelihood of users using Slack in their personal workflows was low.
- Slack’s own interface caused a great deal of confusion for our users.
V1: Chrome Extension
We began developing a Chrome extension in December 2022, primarily to address the issues mentioned above. While Chrome extensions also have friction, users have the option to install them individually. Chrome extensions can also automatically summarize pages that users have visited, achieving the effect of AI as a companion. Additionally, Chrome extensions facilitate better synergy between personal and work use. During the iteration process of the Chrome extension, we realized that chat is one of the most important means of interaction. Users can accurately express their needs by asking questions (or using prompt words). Although we allowed users to ask questions during the Slack phase, the main focus was still on providing a series of buttons. In the iteration process of the Chrome extension, we discovered that the chat interface is very flexible and can quickly uncover customer needs that weren’t predefined.
On January 17th, we released our Chrome extension. However, on February 7th, Microsoft released Bing Chat (later known as Copilot), integrated into Microsoft Edge. By March, the Chrome Store was flooded with Copilot copycats. We quickly realized that the direction Copilot was taking would soon become a saturated market. Additionally, during the development of our Chrome extension, we became aware of some bottlenecks. The friction in developing Chrome extensions is quite high. Google’s Web Store review process takes about a week. This wouldn’t be a problem in traditional software development, but it’s very disadvantageous for the development of large models. This year, the iteration speed of large models is essentially daily. If we update only once a week, it’s easy to fall behind.
V2: VirtualMe™ (Digital Twin)
In March 2023, we began developing our own web-based application. Users can upload their documents or audio and video files, and then we generate summaries, allowing users to ask corresponding questions. Our initial intention was to build a user interaction platform that we could control. The development speed of the web-based application was an order of magnitude faster than the Chrome extension. We could release updates four to five times a day without waiting for Google’s approval. Moreover, with the Chrome extension, we could only use a small part of the browser’s right side. There were many limitations in interaction, but with the web-based platform, we have complete control over user interactions, allowing us to create more complex user-product interactions.
During this process, we learned that it is very difficult to retain users with utility applications. Users typically leave as soon as they are done with the tool, showing no loyalty. Costs remain high. Moreover, with a large number of AI utility tools going global, the field is becoming increasingly crowded.
We began deliberately filtering our users to interview enterprise users and understand their feedback. By June 2023, we realized that the best way to increase user stickiness was to integrate tightly with enterprise workflows. Enterprise workflows naturally result in data accumulation, and becoming part of an enterprise’s workflow enhances the product’s moat.
We started thinking about how our product could integrate with enterprise workflows. We came up with the idea of creating a personified agent. Most of the time when we encounter problems at work, we first ask our colleagues. A personified agent could integrate well with this workflow. We quickly developed a prototype and invited some users for beta testing.
Our initial user scenario envisioned that everyone could create their own digital twin. Users could upload their data to their digital twin so that when they are not online, it could answer questions on their behalf. After launching the product, we found that the most common use case was not creating one’s own digital twin, but creating the digital twin of someone else. For instance, we found that product managers were heavy users of our product. They mainly created digital twins of their customers to ask questions and see how the customers would respond.
During the VirtualMe™ phase, we began to refine our enterprise user persona for the first time. We identified several user personas, mainly 1. Product Managers, 2. Marketing Managers, 3. Customer Success Managers. Their common characteristic is the need to better understand others and create accordingly.
At the end of July, we organized an offline event and invited many users to test our VirtualMe product together. They found our product very useful, but they had significant concerns about the personified agent. Personal branding is very important for our user group. They were worried that what the virtual twin says could impact their personal brand, especially since large models generally still have the potential for “hallucination.”
It was also at this event that users mentioned the part of our product they found most useful was the customizable Data Container and the ability to quickly generate a chatbot. At that time, no other product on the market could do this.
V3: SmartChat™
Starting in August, we began to emphasize data management features based on this approach and launched SmartChat™. In SmartChat™, once users upload data, we automatically extract tags from the content. Users can also customize tags for data management. By clicking on a tag, the ChatBot will converse based on the content associated with that tag. At the same time, we also launched an automation system that runs prompts for users automatically, pushing the results to the appropriate audience via Slack or email.
The following figure shows our North Star Metric (NSM) up to December 1st of this year. At the beginning of the year, during the Slack plugin phase, our NSM was only averaging around 1. During the Chrome Extension phase, our NSM reached the hundreds. VirtualMe™ pushed our NSM up to 5,000.
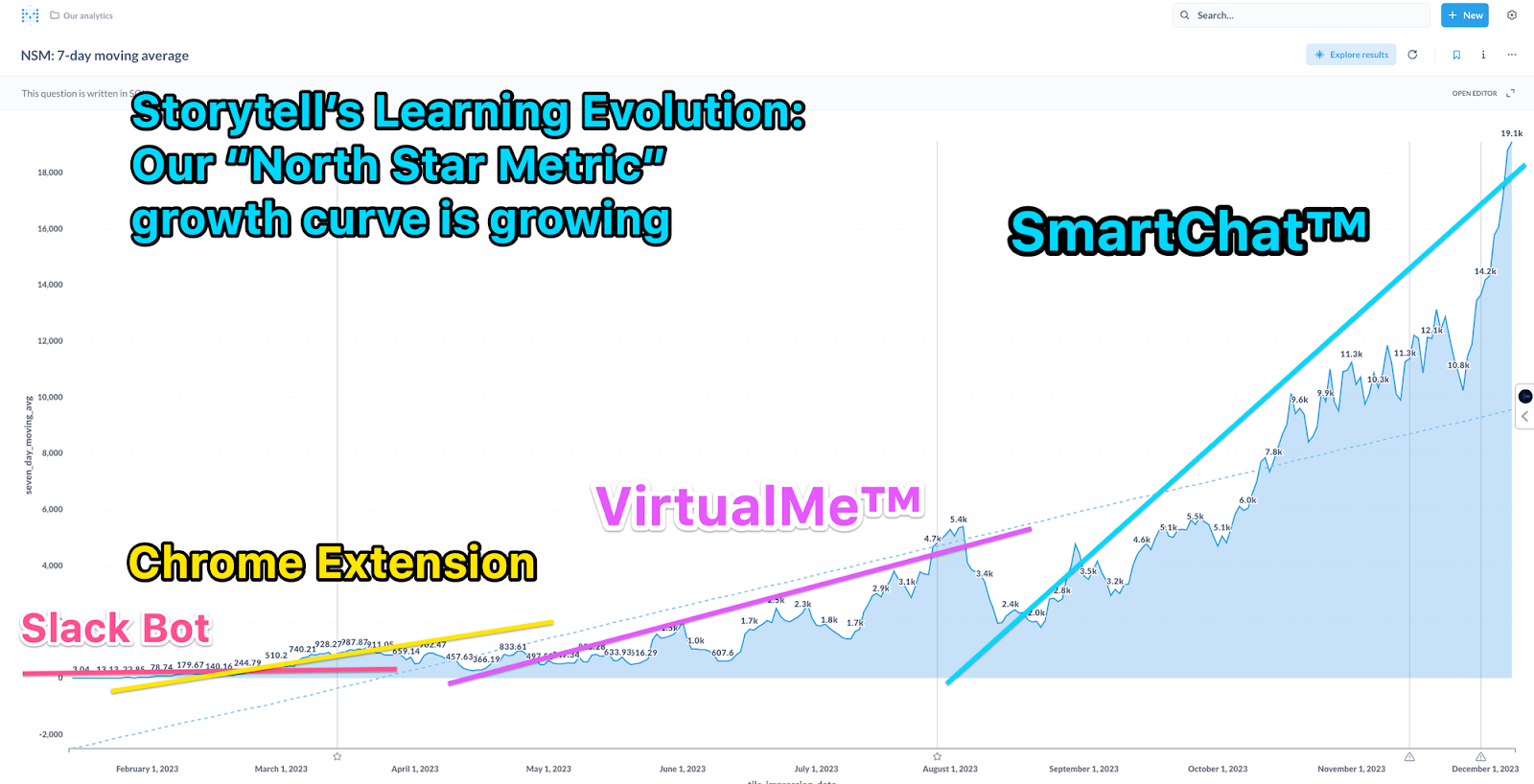
By early December, our NSM was close to 20,000. Previously, our growth was entirely organic. By this time, we felt we could start to do a bit of growth hacking. In December, we started some influencer marketing activities, and our NSM grew by 30 times, reaching 550K!
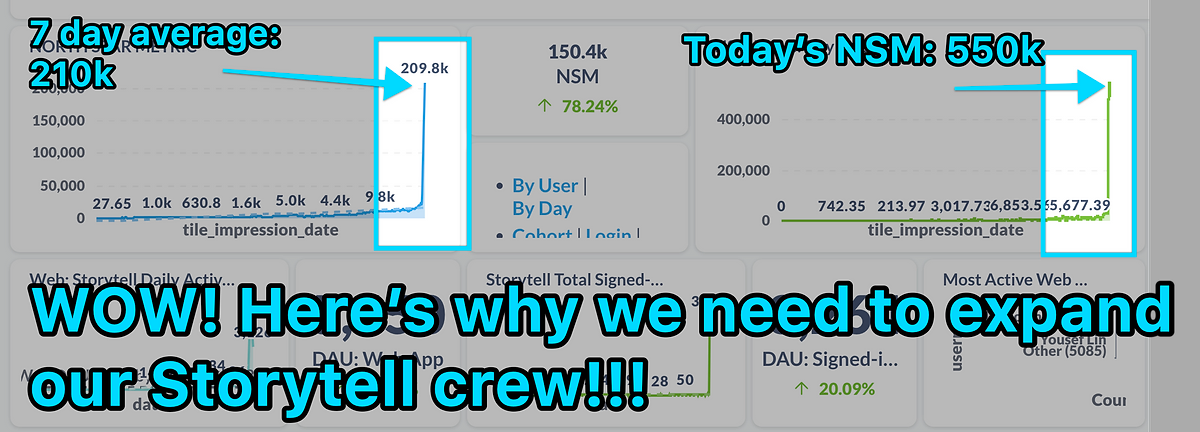
From an NSM of less than 1 at the beginning of the year to 550K by the end of the year, in 2023 we turned Storytell from a demo into a product with a loyal user base. I am proud of our Crew and very grateful to our early users and design partners.
Words at the end
From a young age, I have been particularly fond of reading books on the history of entrepreneurship. The year 2023 marks the beginning of a new era for me to embark this journey. I know the road ahead is challenging, but I am fortunate to experience this process firsthand with my two amazing partners and our Crew. Regardless of the outcome, I will forge ahead with all the Storytell Crew, fearless and without regret. Looking forward to Storytell riding the waves in 2024!
Also, Storytell.ai is hiring front-end and full-stack engineers: https://go.storytell.ai/fse-role. If you are interested or you know anyone might be interested, please don’t hesitate to contact me at my email jingconan@storytell.ai.
