In 1565, Friar Andrés de Urdaneta stood on a deck in Manila, facing the impossible.
Getting to Asia was easy; the trade winds pushed you there. But getting back was a death sentence. For decades, the world’s best navigators had fought the headwinds, ran out of supplies, and died. The “return route” was a graveyard of ambition.
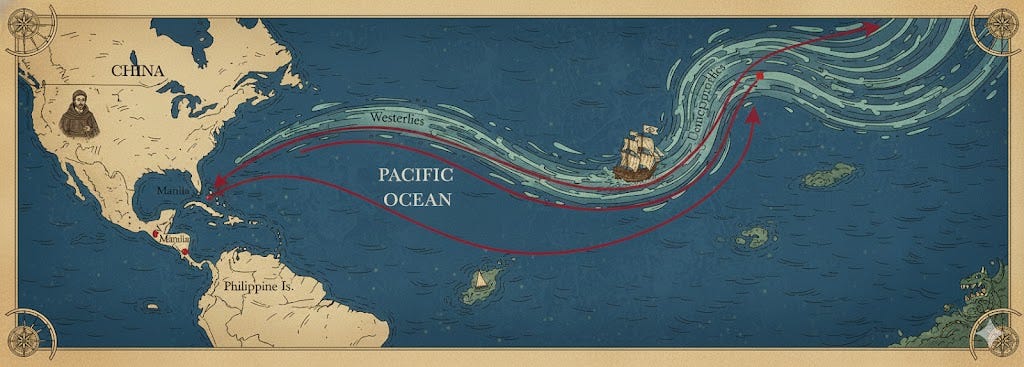
But Urdaneta was a man of data. He realized he couldn’t out-muscle the wind, so he did something that looked like madness: He steered North. Sailing into the freezing 40th parallel, he hunted a current no one else believed in. He found the “Westerlies” jet stream, rode it home to Acapulco, and unlocked the Manila Route—the trade path that sustained an empire for 250 years.
Five centuries later, I see thousands of AI founders standing at their own port of Manila. The ocean before us is the Age of AI, and everyone is looking for their own Manila route—that elusive path to Product-Market Fit (PMF).
The lesson from 1565 is simple: You cannot out-muscle the ocean. You have to study the currents. And right now, three massive trade winds are reshaping the horizon. If you don’t know which one you’re catching, you’re just drifting.
The Three Currents of the AI Ocean
I. The Current of The Crashing Cost
The first current is the most powerful: The crashing cost of the “token.” In the Age of Discovery, the cost of the voyage was the price of spice. Today, it’s the price of intelligence. If your unit economics are underwater, your ship sinks.
Google is currently leading this wave of “Vertical Sovereignty.” They are the only major power sailing on a ship they built from the keel up.
This current is being accelerated by three major powers.
1. Vertical Sovereignty (Google)
Google is leading the trend of Software/Hardware Co-design. A decade ago, they realized they couldn’t afford to buy off-the-shelf chips for global-scale AI.

They built the Tensor Processing Unit (TPU). Unlike a general-purpose GPU, a TPU is an industrial assembly line for math. Its “systolic array” architecture strips away the energy overhead of fetching new instructions. By owning the stack from the silicon to the algorithm, Google can serve models like Gemini 2.5 Flash at price points that are mathematically impossible for anyone paying a “rental tax” on hardware.
2. Huang’s Law (Nvidia)
While Moore’s Law for CPUs has slowed to a crawl, Nvidia’s Jensen Huang is pushing a new reality. Huang’s Law observes that GPU performance for AI is more than doubling every year. Nvidia is relentlessly driving down the cost of compute, meaning the “expensive” feature you can’t afford to build today will be a commodity by the time your product hits the market.
3. The Mixture-of-Experts Wave (Open Source)
The industry’s “Sputnik moment” came from the East. Chinese labs like DeepSeek and Qwen proved that frontier-level intelligence doesn’t require $100M budgets. By using Mixture-of-Experts (MoE)—an architecture that only activates a small fraction of the model for any given task—they shattered the price-to-performance ceiling.
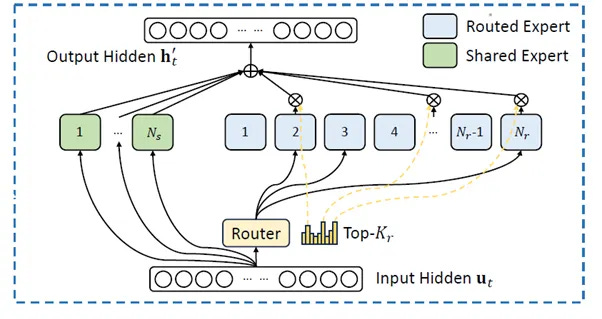
This commoditization of “smart” has forced a chaotic pivot inside Meta, leading to the departure of AI pioneer Yann LeCun. LeCun, an academic purist, refused to become a product manager for a technology he viewed as a mere “off-ramp” on the highway to AGI. His exit signals the end of corporate research charity; efficiency is the only metric that matters now.
II. The Current of Deep Water (Reasoning & Planning)
If Google represents industrial scale, Anthropic represents the “Deep Water” navigators.
In 2023, thousands of “autonomous agents” sank because they were shallow. They could predict the next word, but they couldn’t hold a plan. They would hallucinate a file path in step three and crash by step five. To find PMF in complex workflows, you need Long-Horizon Reasoning.
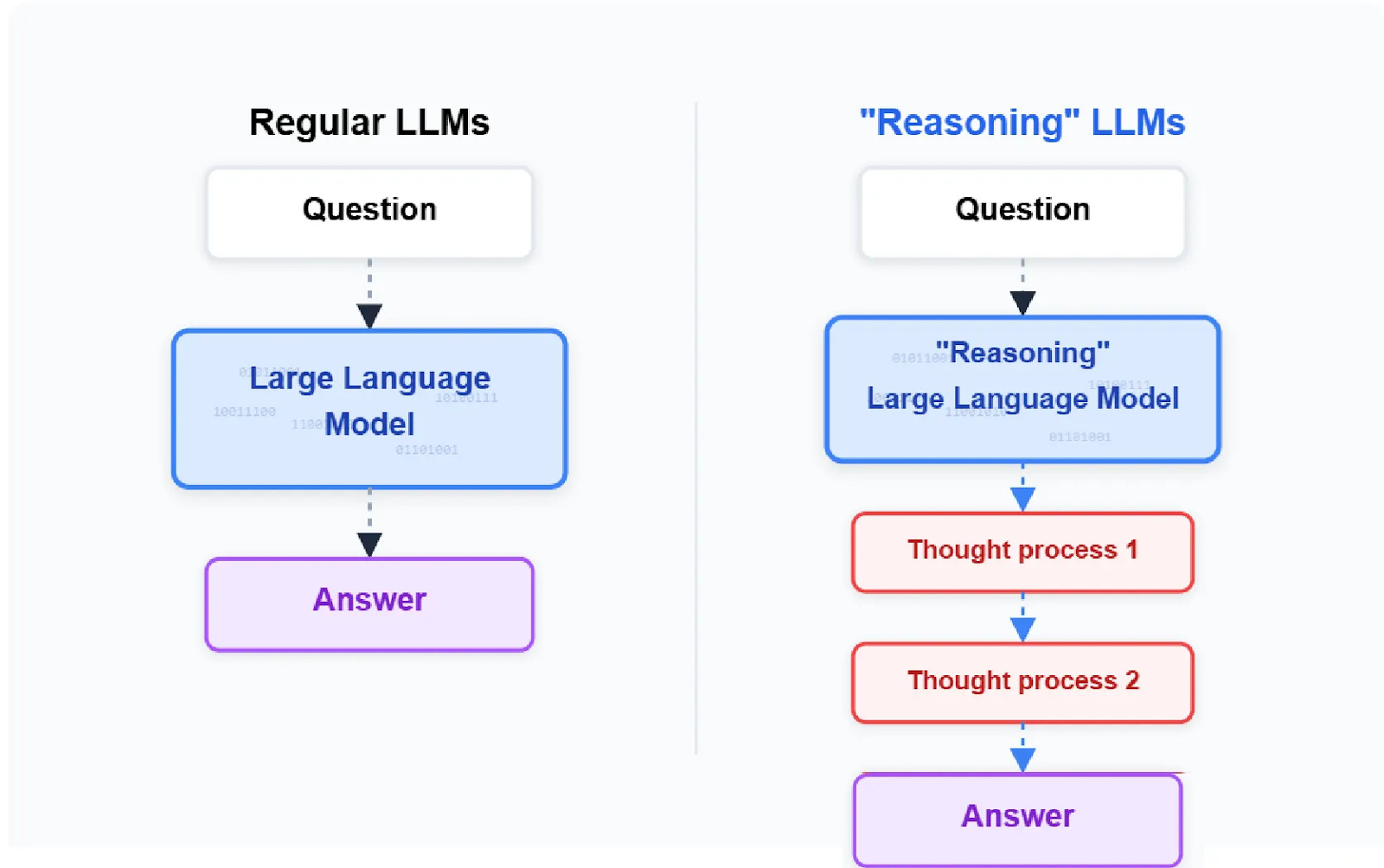
By Joe El Khoury
Anthropic is currently pushing this ceiling higher than anyone else. The release of Claude 3.5 Sonnet was the “Suez Canal” moment for agents—it crossed a logic threshold that finally made autonomous software development and complex auditing viable. While Google and OpenAI are following close behind, Anthropic’s focus on the “Digital Employee”—tools that can plan, click, and execute—is the current that founders building agentic workflows must catch.
III. The Current of Native Fluency (From Text to Multimodal)
The final current is the move from text-only brains to Native Multimodality. The ocean is no longer just words; it is pixels, sound waves, and real-time frames.
Google is leading the charge here by moving away from “Bolt-on” models. Most models today glue a separate vision encoder onto a text brain—it’s fast to build, but “lossy.” The model looks at the world through a foggy window. Google’s Gemini 3.0 was trained from day one on a “mixed soup” of tokens.
This native design is the reason for Gemini’s “agentic fluidity.” It doesn’t watch a video and then think; it thinks while it watches. It can react, laugh, or code in real-time without the lag of translation layers. If your startup requires human-speed interaction, you cannot fight the friction of modular models.
Navigation Tip: You Must Sail North to Go East
This is the hardest part for any founder. The destination (Profitability/PMF) is East. And your logic will say: Steer East.
But Urdaneta knew that steering East meant death because the trade winds were blowing against him. He had to go North. Into the cold. Into the unknown. This was to catch the current that would eventually carry him home.
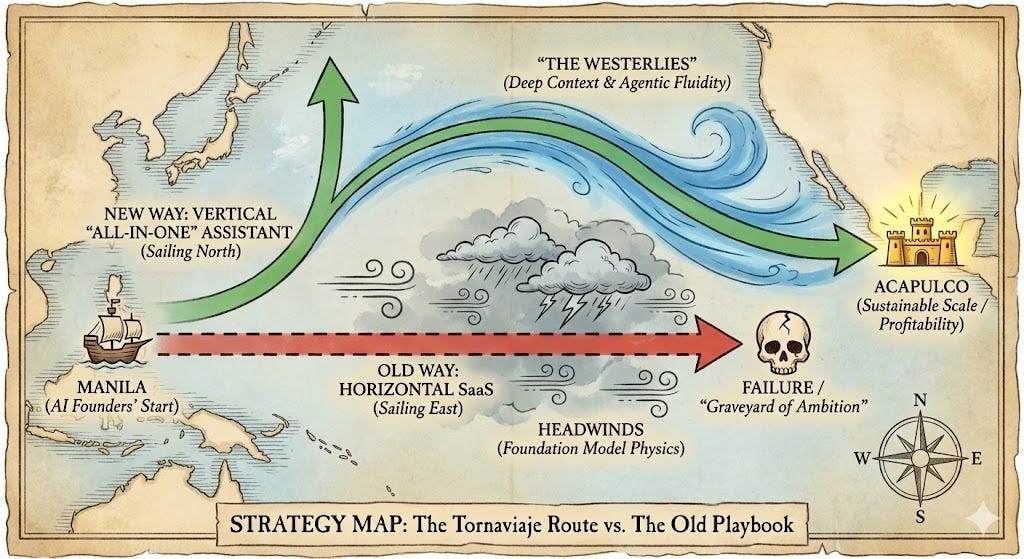
If you want to find your Manila Route, you have to stop thinking like a software vendor and start thinking like a lead navigator. I’ve seen too many founders sink because they stayed in the “safe” shallow waters of generic features.
- Hunt for “Contextual Friction”: Horizontal models (the “East” route) fail when they encounter fragmented data. In the coffee shop example, the “East” path is a generic AI social media scheduler. The “North” path is an AI that has a live API connection to the shop’s POS system, the local weather feed, and the supplier’s inventory. Your goal is to be the glue between data sources that have never talked to each other before.
- Build the “System of Record”: Wrappers die because they don’t own the data. To survive, you must become the place where the work lives. If you are the platform where the staff schedule is created and the inventory is tracked, you own the “Ground Truth.” Generalist models can’t compete with you because they don’t have access to the live state of the business.
- Choose Your “Current” Wisely: * If you are building for high-volume, low-margin industries (like retail or logistics), catch the Google/TPU current. Focus on efficiency and cost-per-task. If you are building for high-stakes, complex reasoning (like medical or legal), catch the Anthropic current. Focus on long-horizon planning and tool-use precision.
- The “Wedge” Strategy: You don’t need to capture the whole market on day one. Pick one “impossible” problem (e.g., “AI that handles late-night supplier disputes for independent bakeries”). Once you’ve mastered the context for that one task, the current of your expertise will naturally pull you into the adjacent markets.
Once Urdaneta mapped the route, the secret was out. For the next two and a half centuries, every Spanish galleon took the exact same path.
Old, antique map of Southeast Asia by F. De Wit.
The same is true for us. The ocean of AI opportunities feels infinite, but the number of truly sustainable business models is limited. The “Manila Route” in the AI landscape will be dominated by the first fleet that maps the currents correctly.
We are entering a period where “luck” will be indistinguishable from “preparation.”
The ocean is vast. The currents are strong. But the route is there for those bold enough to chart it.
Finding the Atlas Together
In the Age of Discovery, no captain sailed entirely alone.
The greatest accelerator of exploration wasn’t better sails or stronger hulls—it was the shared logbook. Every time a navigator returned and shared his charts, the entire world got a little bigger, and the ocean got a little less deadly. The map of the modern world wasn’t drawn by a single genius; it was drawn by a thousand different hands, layering their hard-won secrets over one another.
We are doing the same thing here. The ocean of AI is too vast, and the currents move too fast, for any single captain to map in isolation. We are building FounderCoHo to be the exchange where we can swap charts, warn each other of the storms, and mark the clear passages.
This story—the Manila Route—is just one coordinate in a much larger journey. We are working on a full series of these narratives to help founders build a clear, reliable mental map for the road ahead. But we cannot draw the whole atlas ourselves.
We need your coordinates.
Do you have a story of a “North Turn” that saved your company? Have you found a current that the rest of the industry is missing? Or do you have a warning about a reef you hit in the dark?
Reply to this and tell us your story. We want to build this atlas together, so we can all find our way home.
If this chart helped you find your bearings, please feel free to connect with the author Jing Conan Wang
Stay tuned for the next chart!
Follow FounderCoHo Linkedin Page
References:
- https://www.britannica.com/biography/Andres-de-Urdaneta
- https://read.dukeupress.edu/hahr/article/47/2/261/158102/Friar-Andres-de-Urdaneta-O-S-A
- https://cloud.google.com/transform/ai-specialized-chips-tpu-history-gen-ai
- https://medium.com/data-science-collective/the-origins-rise-and-evolution-of-the-tpu-672a0e4f1a2d
- https://www.datacamp.com/blog/claude-sonnet-anthropic
- https://www.sciencedirect.com/science/article/pii/S2666764925000451
- https://www.bbc.com/news/articles/cdx4x47w8p1o
- https://sanderusmaps.com/our-catalogue/antique-maps/asia/southeast-asia/old-antique-map-of-southeast-asia-by-f-de-wit-24650?srsltid=AfmBOoqOdLKh_Yw4ge6MW0Nlit6kr8CqvkY8MMl4jLdAofT0WOW9J3mA
- https://cloud.google.com/transform/ai-specialized-chips-tpu-history-gen-ai’
- https://medium.com/@jelkhoury880/advancing-ai-reasoning-a-comprehensive-report-4982b7c19bdc
- https://ai.gopubby.com/inside-deepseek-v3-80283167673b