Andrej Karpathy, a prominent voice in the AI community, recently brought the term “Context Engineering” to the forefront. It describes the intricate art of manually crafting prompts and data to guide Large Language Models. While the concept is gaining significant attention, I believe it points us in the wrong direction.
The future of personal AI isn’t about endlessly engineering context, but requires a radical shift to what I call ‘context modeling.’
This isn’t just semantics—it’s the difference between a temporary patch and a real solution.
The Limitations of Current RAG Systems
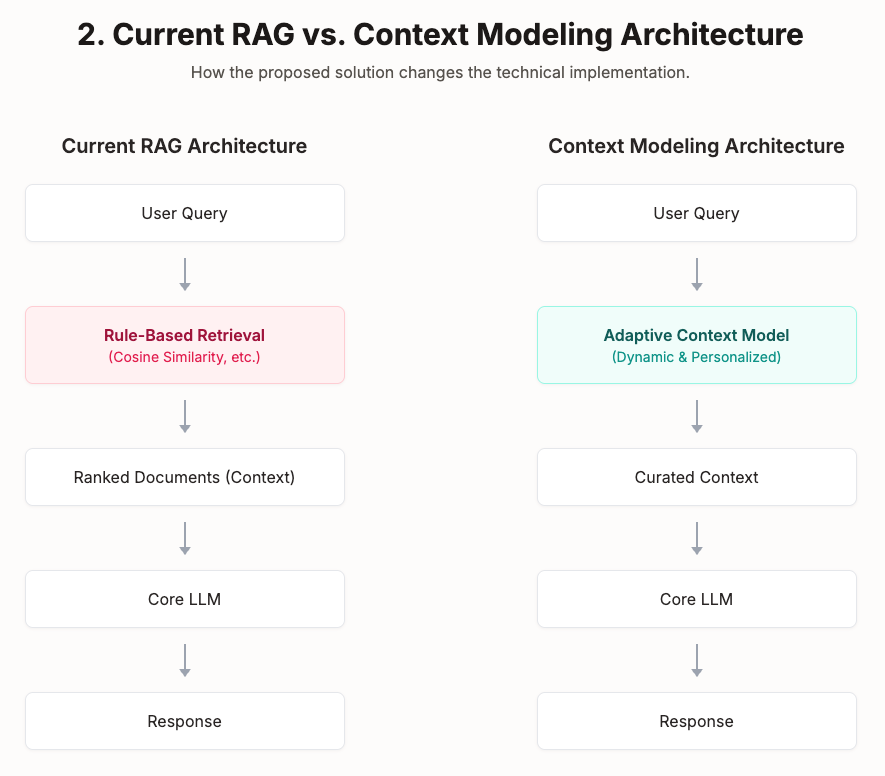
Today’s Retrieval-Augmented Generation (RAG) systems follow a relatively straightforward paradigm. They retrieve relevant information using rule-based systems—typically employing cosine similarity to find the top-k most relevant results—and then present this context to a large language model for processing. While this approach has proven effective in many scenarios, it suffers from significant limitations.
Think of current LLMs as exceptionally intelligent but stubborn team members. They excel at processing whatever information is presented to them, but they interpret data through their own fixed worldview. As these models become larger and more complex, they also become increasingly “frozen” in their approaches, making it difficult for developers to influence their internal decision-making processes.
From Engineering to Modeling: A Paradigm Shift
The conventional approach of context engineering focuses on creating more sophisticated rules and algorithms to manage context retrieval. However, this misses a crucial opportunity. Instead of simply engineering better rules, we need to move toward context modeling—a dynamic, adaptive system that generates specialized context based on the current situation.
Context modeling introduces a personalized model that works alongside the main LLM, serving as an intelligent intermediary that understands both the user’s needs and the optimal way to present information to the large language model. This approach recognizes that effective AI systems require more than just powerful models; they need intelligent context curation.

Learning from Recommendation Systems
The architecture for context modeling draws inspiration from the well-established two-stage recommendation systems that power many of today’s most successful platforms. These systems consist of:
- Retrieval Stage: A fast, efficient system that processes large amounts of data with a focus on recall and speed.
- Ranking Stage: A more sophisticated system that focuses on accuracy, distilling signal from noise to produce the best results.
RAG systems fundamentally mirror this architecture, with one key difference: they replace the traditional ranking component with large language models. This substitution enables RAG systems to solve open-domain problems through natural language interfaces, moving beyond the limited ranking problems that traditional recommendation systems address.
However, current RAG implementations have largely overlooked the potential for model-based retrieval in the first stage. While the industry has extensively explored rule-based retrieval systems, the opportunity for intelligent, adaptive context modeling remains largely untapped.
The Context Modeling Solution
Context modeling addresses this gap by introducing a specialized model dedicated to generating context dynamically. This model doesn’t need to be large or computationally expensive—it can be a focused, specialized system trained on relevant data that understands the specific domain and user needs.
The key advantages of context modeling include:
- Adaptability: Unlike rule-based systems, context models can learn and adapt to new patterns and user behaviors over time.
- Personalization: These models can be trained on user-specific data, creating truly personalized AI experiences that understand individual contexts and preferences.
- Efficiency: By using smaller, specialized models for context generation, the system maintains efficiency while providing more intelligent context curation.
- Developer Control: Context modeling provides agent developers with a trainable component they can influence and improve, creating opportunities for continuous learning and optimization.
The Ideal Architecture: Speed and Specialization
For context modeling to be viable, it must satisfy one critical requirement: speed. The latency of the core LLM is already a significant bottleneck in user experience.
Right now, the main workaround is streaming the response. However, the latency to the first token cannot be mitigated by streaming. The end-to-end latency of the retrieval model contributes to the latency of the first token. Any context modeling system must be exceptionally fast to avoid compounding this delay.
This brings us to the concept of “thinking” models, which use their own internal mechanisms to retrieve and reason over context before generating a final answer. In a sense, these models perform a specialized form of context modeling. However, their primary challenge is that this “thinking” process is slow and computationally expensive.
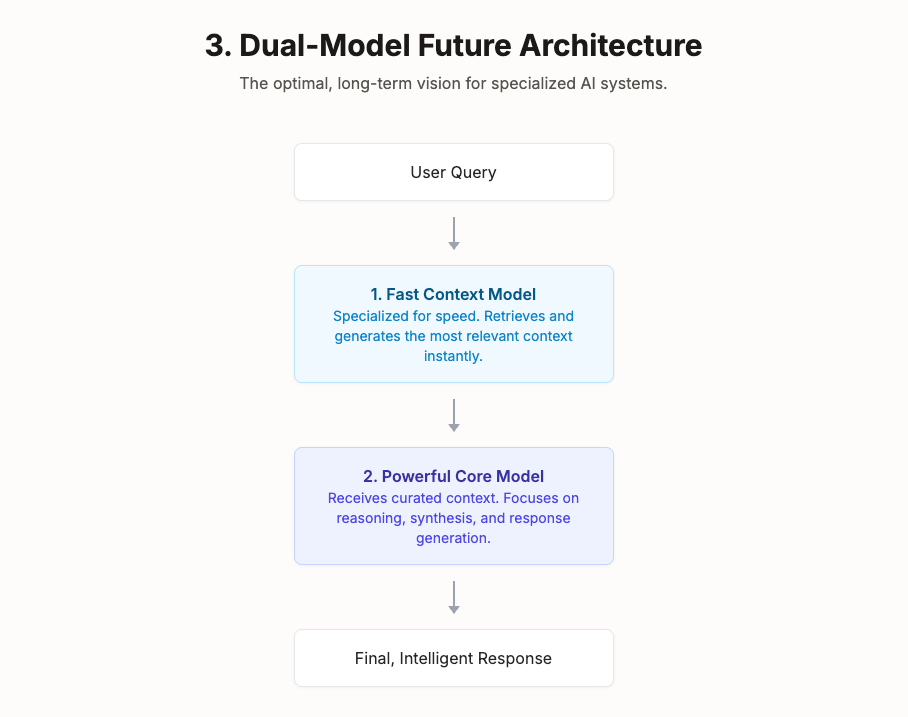
I argue that these monolithic “thinking” models are an intermediate step. The optimal, long-term architecture will decouple the two primary tasks. It will feature two distinct models working in tandem, mirroring the two-stage systems that have been so successful in recommendations:
- A Fast Context Model: A highly optimized, specialized model dedicated solely to retrieving and generating the most relevant context at incredible speed.
- A Powerful Core Model: The large language model that receives this curated context and focuses on the complex task of reasoning, synthesis, and final response generation.
This dual-model approach allows for specialization, where each component can be optimized for its specific task, delivering both speed and intelligence without compromise.
The Infrastructure Opportunity
Context modeling represents a common infrastructure need across the AI industry. As more organizations deploy RAG systems and AI agents, the demand for sophisticated context management will only grow. This presents an opportunity to build foundational infrastructure that can support a wide range of applications and use cases.
The development of context modeling systems requires expertise in both machine learning and system design, combining the lessons learned from recommendation systems with the unique challenges of natural language processing and generation.
Looking Forward
The future of personalized AI lies not in building ever-larger language models, but in creating intelligent systems that can effectively collaborate with these powerful but inflexible models. Context modeling represents a crucial step toward this future, enabling AI systems that are both powerful and adaptable.
As we move forward, the organizations that successfully implement context modeling will have a significant advantage in creating AI systems that truly understand and serve their users. The shift from context engineering to context modeling isn’t just a technical evolution—it’s a fundamental reimagining of how we build intelligent systems that can adapt and personalize at scale.
The question isn’t whether context modeling will become the standard approach, but how quickly the industry will recognize its potential and begin building the infrastructure to support it. The future of personalized AI depends on our ability to move beyond static rules and embrace dynamic, intelligent context generation.
Questions or feedback? I’d love to hear your thoughts.
Want more insights? Follow me:
🎙️ Founder Interviews: https://www.youtube.com/@FounderCoHo
Conversations with successful founders and leaders.
🚀 My Journey: https://www.youtube.com/@jingconan
Building DeepVista from the ground up.
