Jing Conan Wang is the co-founder and CEO of Hachi AI. At Hachi AI, we believe that AI can do much more than serve as assistants; they can be our friends. Our goal is to build Large Language Models (LLMs) that interact with you just like real friends, providing joy and companionship.
Jing is a domain expert and pioneer in the LLM space.
From early 2022 to 2024, Jing co-founded and served as the founding CTO of Storytell.ai, a startup focused on using LLMs to turn unstructured data into actionable insights. He founded Storytell.ai based on his unique insight that LLMs have the innate ability to help humans distill signals from noise through conversations, a concept later popularized by ChatGPT.
From 2019 to 2022, he was a founding member and Head of Science & ML at Intellimize, a B2B SaaS startup that dynamically personalized websites for each unique visitor in real time (acquired by Webflow). At Intellimize, he also led efforts to use generative AI to create marketing campaigns.
From early 2018 to 2019, he was a Senior Research Engineer at Google Brain, where he applied reinforcement learning-based approaches to align humans and LLMs, as well as other deep learning models. His inventions have been integrated into various Google products, significantly improving core systems like YouTube and Google Ads.
Prior to Google Brain, he worked at Google Ads between 2014 and 2017, where he drove 20+ modeling launches that bring Google more than $200M in revenue annually.
He obtained a Ph.D. degree from Boston University (advisor: Yannis Paschalidis) and B.E. degree from Huazhong Univ. of Sci. and Tech.
He has good knowledge of mathematical modeling. He received a prize of Honorable Mention in Mathematical Contest in Modeling (MCM) 2009, and the second prize in the Chinese Undergraduate Mathematical Contest in Modeling (CUMCM) 2009. He has extensive experience in research and open-source development. He was a participant of Google Summer of Code 2012 and a mentor for Google Summer of Code 2013, both for the Honeynet Project. He was a finalist for Microsoft Young Fellow in 2009.
Recently, there’s been an interesting development in the big model industry. Perplexity AI, a hot big model company in Silicon Valley, completed a financing round two months ago, valuing it at over $500 million. However, using Lepton AI’s middleware, Lepton’s co-founder Jiayang Qing managed to create an open-source version with just 500 lines of code over a weekend, sparking a heated discussion in the industry. The related demo on GitHub quickly garnered five thousand stars in just a few days. This incident reflects a broader trend, and I’ll analyze it based on my own year and a half of entrepreneurial experience.
Currently, big model companies can be categorized into three types:
Base model companies, which primarily provide big model capabilities. This area requires significant capital and resources are highly concentrated among leading companies and giants.
Middleware companies, which offer middleware between big models and applications. Jiayang Qing’s Lepton AI falls into this category.
Application-layer companies, which directly provide consumer-facing applications. These can further be divided into platform-type application companies, like Perplexity AI, and vertical application companies focusing on niche markets, such as Harvey AI, which recently completed financing for its legal application.
The incident with Perplexity AI and Lepton AI highlights a pain point for application-layer companies — high competitive pressure with insufficient moats. For instance, Perplexity, which aims to solve general information search problems, faces challenges from four fronts: pressure from giants like Google, competition from vertical knowledge applications like Harvey, market encroachment from other knowledge service companies, and disruptions from middleware companies like Lepton AI. Vertical application companies face slightly less pressure, but they still confront these four forces and have a smaller market size, resulting in fewer resources.
So, what can be done? Many entrepreneurs believe that accumulating proprietary data can create a sufficient moat. This is very sensible, but it presupposes a systematic methodology for acquiring proprietary data. Here, I propose a methodology: using contrarian insights to gain a time advantage, leveraging the founder’s personal strengths for breakthroughs, and focusing on data-first products or operational capabilities.
First, contrarian insights, or insights not commonly understood, are essential. Entrepreneurs must find less trodden paths to build their core competitive advantage with minimal resources. What was once a contrarian insight can become common knowledge, such as the combination of big models with chat interfaces, which was novel before ChatGPT but is now common.
Second, the founder’s personal advantage is crucial. While contrarian insights offer temporary protection, they quickly become common knowledge once proven useful. Here, a deep understanding of user pain points in vertical applications can be a personal advantage. For example, one of Harvey’s co-founders was a lawyer. Even if a team doesn’t have a co-founder from a specific industry, previous experiences that can be leveraged as industry advantages are valuable.
Finally, building a data-first product or operational capability is key. The founder’s personal advantage must be systematized to sustain. There are two strategies:
Product-driven: The founder uses their deep understanding of user needs to design a product that naturally accumulates high-quality data, enhancing the product experience and creating a flywheel effect.
Operation-driven: The founder uses their resources and experience to build an operational system that continually acquires proprietary data, making operations or sales more efficient and faster.
The former suits products focused on Product-led Growth (PLG), while the latter suits those driven by Sales-led Growth (SLG). Both must prioritize data. If product-driven, each feature should contribute to data accumulation. If operation-driven, operations should focus on data, not just revenue or other metrics.
Returning to Perplexity’s case, Jiayang Qing could replicate Perplexity’s main functions over a weekend but not its data accumulation. As a middleware company, Lepton likely doesn’t intend this as a core strategy. However, many new application startups may use this to challenge Perplexity further. Whether Perplexity can withstand this depends on its ability to build a moat with proprietary data.
My name is Jing Conan Wang, a co-founder and CTO of Storytell.ai. In October 2022, together with two amazing partners DROdio and Erika, we founded Storytell.ai, dedicated to distilling signal from noise to improve the efficiency of knowledge workers. The reason we chose the name Storytell.ai is that storytelling is the oldest tool for knowledge distillation in human history. In ancient times, people sat around bright campfires telling stories, allowing human experiences and wisdom to be passed down through generations.
The past year has been an explosive one for large language models (LLMs). With the meteoric rise of ChatGPT, LLMs have quickly become known to the general public. I hope to share my own personal story to give people a glimpse into the grandeur of entrepreneurship in the field of large language models.
From Google and Beyond
Although ChatGPT comes from OpenAI, the roots of LLMs lie in Google Brain – a deep learning lab founded by Jeff Dean, Andrew Ng, and others. It was during my time at Google Brain that I formed a connection with LLMs. I worked at Google for five years, spending the first three in Ads engineering and the latter two in Google Brain. Not long after joining Google Brain, I noticed that one colleague after another began shifting their focus to research on large language models. That period (2017-2019) was the germination phase for LLMs, with a plethora of new technologies emerging in Google’s labs. Being in the midst of this environment allowed me to gain a profound understanding of the capabilities of LLMs. Particularly, there were a few experiences that made me realize that a true technological revolution in language models was on the horizon:
One was about BERT — one of the best LLMs before ChatGPT: One day in 2017, while I was in a Google Cafe, a thunderous applause broke out. It turned out that a group nearby was discussing the results of an experiment. Google provides free lunches for its employees, and lunchtime often brings people together to talk about work. A colleague mentioned to me: “Do you know about BERT?” At the time, I only knew BERT as a character from the American animated show Sesame Street, which I had never watched. My colleague told me: “BERT has increased Google Search revenue by 1% in internal experiments.” Google’s revenue was already over a hundred billion dollars a year, meaning this was equivalent to several billion dollars in annual revenue. This was quite shocking to me.
Another was my experience with Duplex: Sunder Pichai released a demo of an AI making phone calls at Google I/O 2018, which caused a sensation in the industry. The project, internally known as Duplex, was something our group was responsible for in terms of related model work. The demo only showed a small part of what was possible; internally, there was a lot more data on similar AI phone calls. We often needed to review the results of the Duplex model. The outcome was astonishing; I could hardly differentiate between conversations held by AI or humans.
Another gain was my reflection on business models. Although I had worked in Google’s commercialization team for a long time and the models I personally worked on generated over two hundred million dollars in annual revenue for Google, I realized that an advertising-driven business model would become a shackle for large language models. The biggest problem with the advertising business model is that it treats users’ attention (time) as a commodity for sale. To users, it seems like they are using the product for free, but in reality, they are giving their attention to the platform. The platform has no incentive to increase user efficiency but rather to capture more attention to sell at a very low price. Valuable users will eventually leave the platform, leading to the platform itself becoming increasingly worthless.
One of the AI applications I worked on at Google Brain was the video recommendation on YouTube’s homepage. The entire business model of Google and YouTube is based on advertising; longer user watch time means more ad revenue. Therefore, for applications like YouTube, the most important goal is to increase the total time users spend on the app. At that time, TikTok had not yet risen, and YouTube was unrivaled in the video domain in the United States. In YouTube’s model review meetings, we often joked that the only way for us to get more usage is to reduce the time people spend eating and sleeping. Although I wanted to improve user experience through better algorithms, no matter how I adjusted, the ultimate goal was still inseparable from increasing user watch time to boost ad revenue.
During my contemplation, I gradually encountered the Software as a Service (SaaS) business model and felt that this was the right model for large-scale models. In SaaS, users only pay for subscriptions if they receive continuous value. SaaS is customer-driven, whereas Google’s culture overly emphasizes an engineering culture and neglects customer value, making it very difficult to explore this path within Google. Ultimately, I was determined to leave Google and decided to start my own SaaS company. At the end of 2019, I joined a SaaS startup as a Founding Member and learned about the building process of a SaaS company from zero to one.
At the same time, I was also looking for good partners. Finally, in 2021 I was able to meet two amazing partners DROdio and Erika and we started storytell.ai in 2022.
Build a company of belonging
The first thing we did at the inception of our company was to clarify our vision and culture. We want to build a company of belonging by defining our vision and culture clearly. The vision and culture of a company truly define its DNA; the vision helps us know where to go, and the culture ensures we work together effectively.
Storytell’s vision is to become the Clarity Layer, using AI to help people distill signal from noise (https://go.storytell.ai/vision). — a company with great vision and culture.
We have six cultural values: 1) Apply High-Leverage Thinking. 2) Everyone is Crew. 3) Market Signal is our North Star. 4) We Default to Transparency. 5) We Prioritize Courageous Candor in our Interactions. 6) We are a Learning Organization. Please refer to this https://go.Storytell.ai/values for details.
We also pay special attention to team culture building during the company’s creation process. From the start, we hope to work hard but also play harder. We have offsite gatherings every quarter. The entire team is very fond of outdoor activities and camping, so we often hold various outdoor events (we have a shared album with photos from the very first day of our establishment). We call ourselves the Storytell Crew, hoping that we can traverse the stars and oceans together like an astronaut crew.
Build a Product that people love
In the early stages of a startup, finding Product-Market Fit (PMF) is of utmost importance. Traditional SaaS software emphasizes specialization and segmentation, with typically only a few companies iterating within each niche, and product stability may take years to achieve. This year, ChatGPT brought about a radical market change. The explosive popularity of ChatGPT is a double-edged sword for SaaS software entrepreneurs. On one hand, it reduces the cost of educating the market; on the other hand, the entire field becomes more competitive, with a surge of entrepreneurs entering the market and diverting customer resources. The influx of ineffective traffic brought by ChatGPT ultimately fails to convert effectively into the product.
Many believe that the moat for startups applying large models is technology or data. We think neither is the case. The real moat is the skill in wielding this double-edged sword. Good swordsmanship can transform both edges of the sword into a force that breaks through barriers:
On one hand, for traditional SaaS, it’s about leveraging the momentum of ChatGPT to maximize the impact on traditional SaaS. Make customers feel the urgency to keep up with the times. Develop AI Native features that incumbents find hard to follow.
On the other hand, use the competition to bring about a thriving ecosystem and have a methodical and steadfast approach in product iteration, ultimately shortening the product iteration cycle to achieve the greatest momentum.
We follow these two principles in our own product iteration.
1) Data-guided: In the iteration process, we use the North Star Metric to guide our general direction. Our North Star Metric is:
Effective Reach = Total Reach x Effective Ratio
Total reach is the number of summaries and questions asked on our platform each day. The Effective Ratio is a number from 0 to 1 that indicates how much of the content we generate is useful for users.
2) User-driven. Drive product feature adjustments through in-depth communication with users. For collecting user feedback, we’ve adopted a combination of online and offline methods. Online, we use user behavior analysis tools to identify meaningful user actions and follow up with user interviews to collect specific feedback. Offline, we organize many events to bring users together for brainstorming sessions.
With this approach in mind, our product has undergone multiple rounds of iteration in the past year.
V0: Slack Plugin
Since June 2022, Erika, DROdio and I have been conducting numerous customer discovery calls. During our interviews with users, we often needed to record the conversations. We primarily used Zoom, but Zoom itself did not provide a summarization tool back then. I used the GPT-3 API to create a Slack plugin that automatically generates summaries. Whenever we had a Zoom meeting, it would automatically send the meeting video link to a specific Slack channel. Subsequently, our plugin would reply with an auto-generated summary. Users could also ask some follow-up questions in response.
At that time, there weren’t many tools available for automatically generating summaries, and every user we interviewed was amazed by this tool. This made us gradually shift our focus towards the direction of automatic summarization. The Slack plugin allowed us to collect a lot of user feedback. By the end of December 2022, we realized the limitations of the Slack plugin.
Firstly: Slack is a system with high friction. Only system administrators can install plugins; regular employees cannot install plugins themselves.
We had almost no usage of our Slack plugin over the weekends. The likelihood of users using Slack in their personal workflows was low.
Slack’s own interface caused a great deal of confusion for our users.
V1: Chrome Extension
We began developing a Chrome extension in December 2022, primarily to address the issues mentioned above. While Chrome extensions also have friction, users have the option to install them individually. Chrome extensions can also automatically summarize pages that users have visited, achieving the effect of AI as a companion. Additionally, Chrome extensions facilitate better synergy between personal and work use. During the iteration process of the Chrome extension, we realized that chat is one of the most important means of interaction. Users can accurately express their needs by asking questions (or using prompt words). Although we allowed users to ask questions during the Slack phase, the main focus was still on providing a series of buttons. In the iteration process of the Chrome extension, we discovered that the chat interface is very flexible and can quickly uncover customer needs that weren’t predefined.
On January 17th, we released our Chrome extension. However, on February 7th, Microsoft released Bing Chat (later known as Copilot), integrated into Microsoft Edge. By March, the Chrome Store was flooded with Copilot copycats. We quickly realized that the direction Copilot was taking would soon become a saturated market. Additionally, during the development of our Chrome extension, we became aware of some bottlenecks. The friction in developing Chrome extensions is quite high. Google’s Web Store review process takes about a week. This wouldn’t be a problem in traditional software development, but it’s very disadvantageous for the development of large models. This year, the iteration speed of large models is essentially daily. If we update only once a week, it’s easy to fall behind.
V2: VirtualMe™ (Digital Twin)
In March 2023, we began developing our own web-based application. Users can upload their documents or audio and video files, and then we generate summaries, allowing users to ask corresponding questions. Our initial intention was to build a user interaction platform that we could control. The development speed of the web-based application was an order of magnitude faster than the Chrome extension. We could release updates four to five times a day without waiting for Google’s approval. Moreover, with the Chrome extension, we could only use a small part of the browser’s right side. There were many limitations in interaction, but with the web-based platform, we have complete control over user interactions, allowing us to create more complex user-product interactions.
During this process, we learned that it is very difficult to retain users with utility applications. Users typically leave as soon as they are done with the tool, showing no loyalty. Costs remain high. Moreover, with a large number of AI utility tools going global, the field is becoming increasingly crowded.
We began deliberately filtering our users to interview enterprise users and understand their feedback. By June 2023, we realized that the best way to increase user stickiness was to integrate tightly with enterprise workflows. Enterprise workflows naturally result in data accumulation, and becoming part of an enterprise’s workflow enhances the product’s moat.
We started thinking about how our product could integrate with enterprise workflows. We came up with the idea of creating a personified agent. Most of the time when we encounter problems at work, we first ask our colleagues. A personified agent could integrate well with this workflow. We quickly developed a prototype and invited some users for beta testing.
Our initial user scenario envisioned that everyone could create their own digital twin. Users could upload their data to their digital twin so that when they are not online, it could answer questions on their behalf. After launching the product, we found that the most common use case was not creating one’s own digital twin, but creating the digital twin of someone else. For instance, we found that product managers were heavy users of our product. They mainly created digital twins of their customers to ask questions and see how the customers would respond.
During the VirtualMe™ phase, we began to refine our enterprise user persona for the first time. We identified several user personas, mainly 1. Product Managers, 2. Marketing Managers, 3. Customer Success Managers. Their common characteristic is the need to better understand others and create accordingly.
At the end of July, we organized an offline event and invited many users to test our VirtualMe product together. They found our product very useful, but they had significant concerns about the personified agent. Personal branding is very important for our user group. They were worried that what the virtual twin says could impact their personal brand, especially since large models generally still have the potential for “hallucination.”
It was also at this event that users mentioned the part of our product they found most useful was the customizable Data Container and the ability to quickly generate a chatbot. At that time, no other product on the market could do this.
V3: SmartChat™
Starting in August, we began to emphasize data management features based on this approach and launched SmartChat™. In SmartChat™, once users upload data, we automatically extract tags from the content. Users can also customize tags for data management. By clicking on a tag, the ChatBot will converse based on the content associated with that tag. At the same time, we also launched an automation system that runs prompts for users automatically, pushing the results to the appropriate audience via Slack or email.
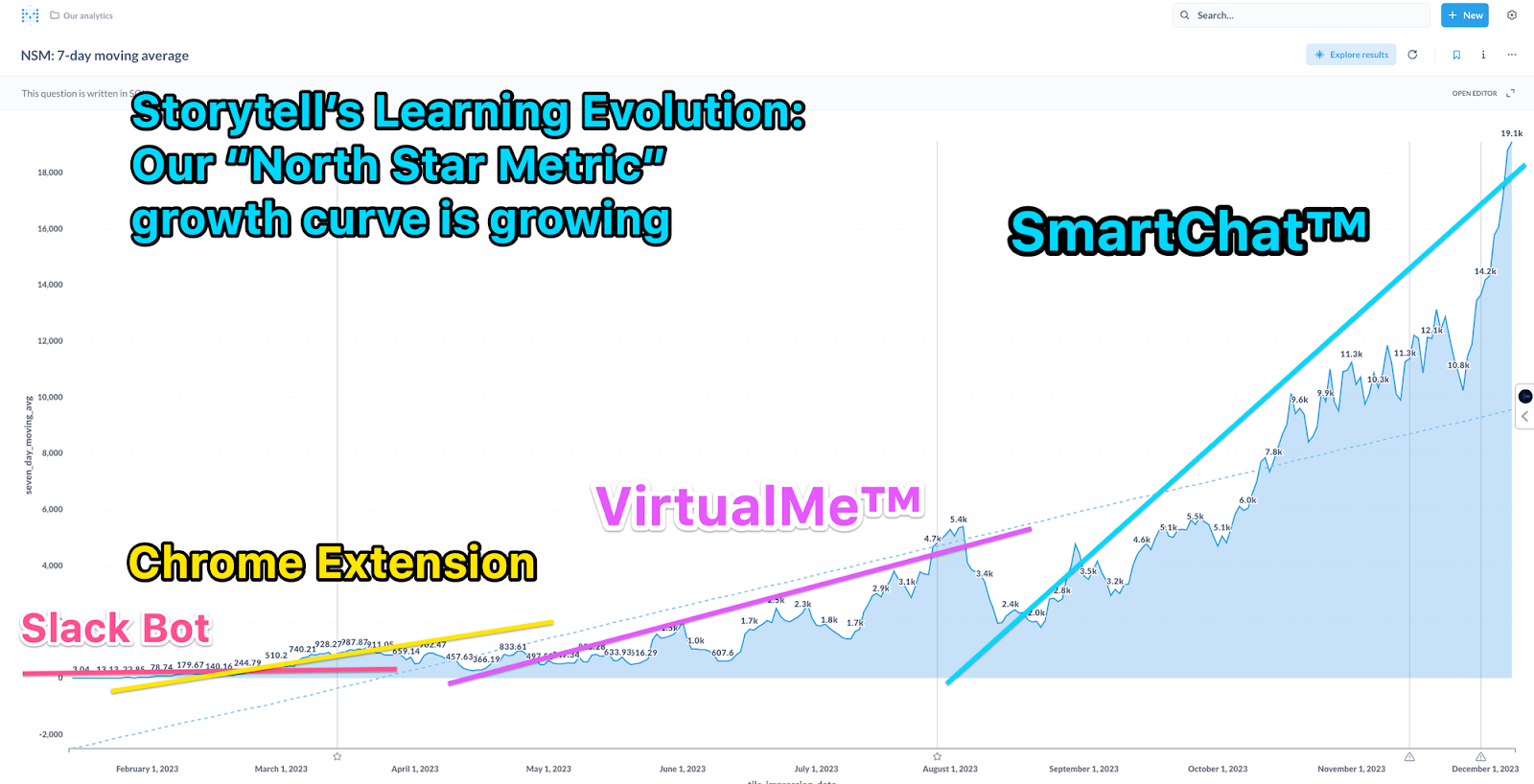
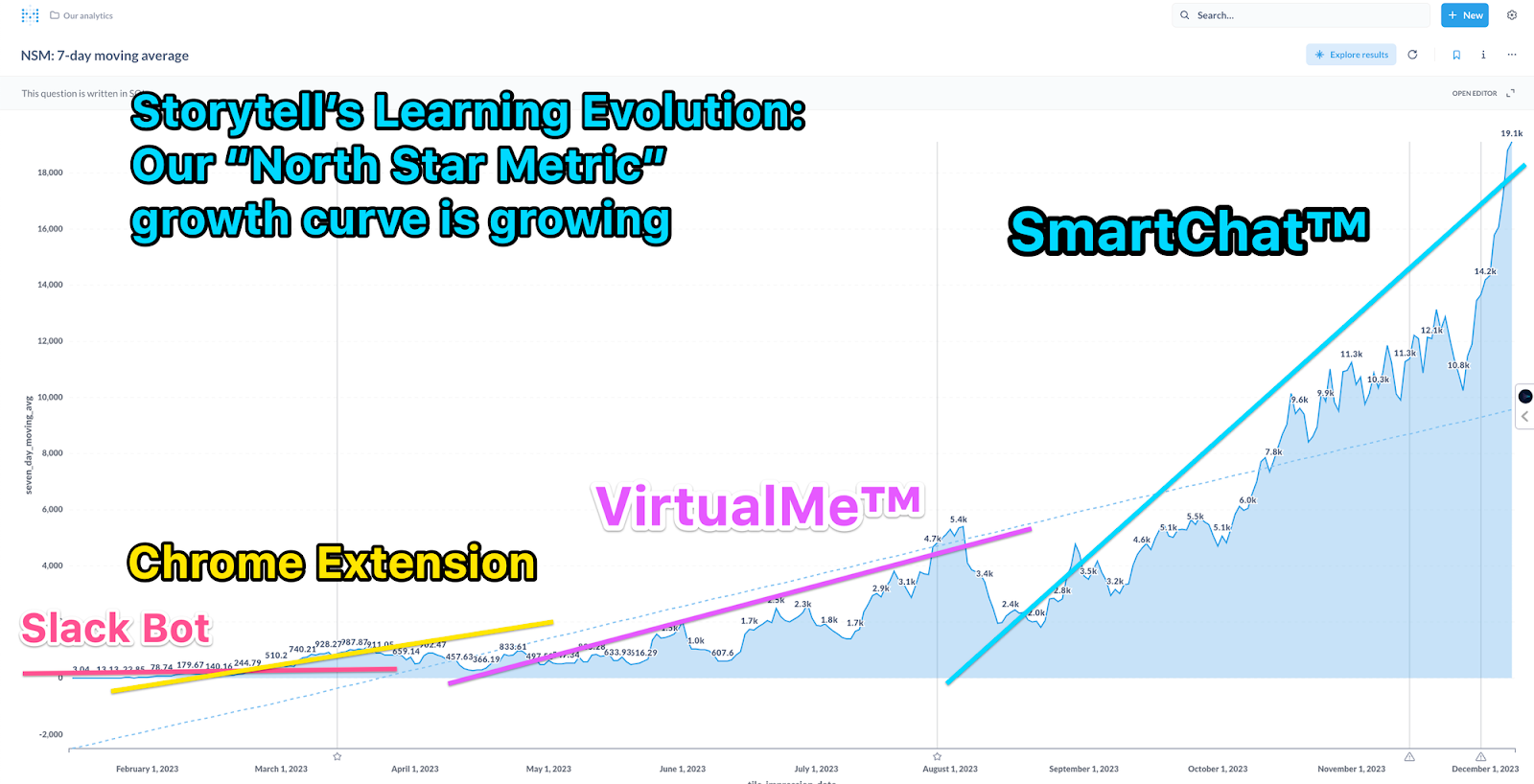
The following figure shows our North Star Metric (NSM) up to December 1st of this year. At the beginning of the year, during the Slack plugin phase, our NSM was only averaging around 1. During the Chrome Extension phase, our NSM reached the hundreds. VirtualMe™ pushed our NSM up to 5,000.
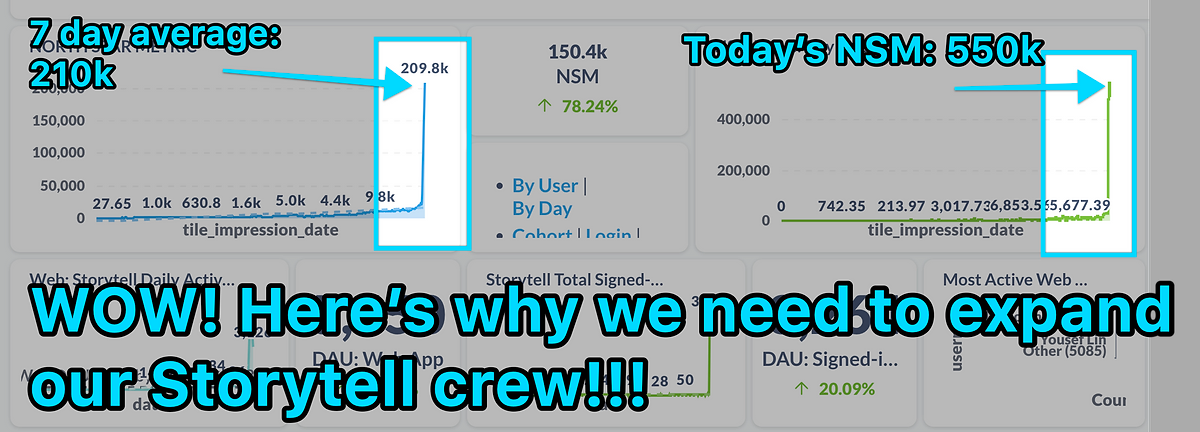
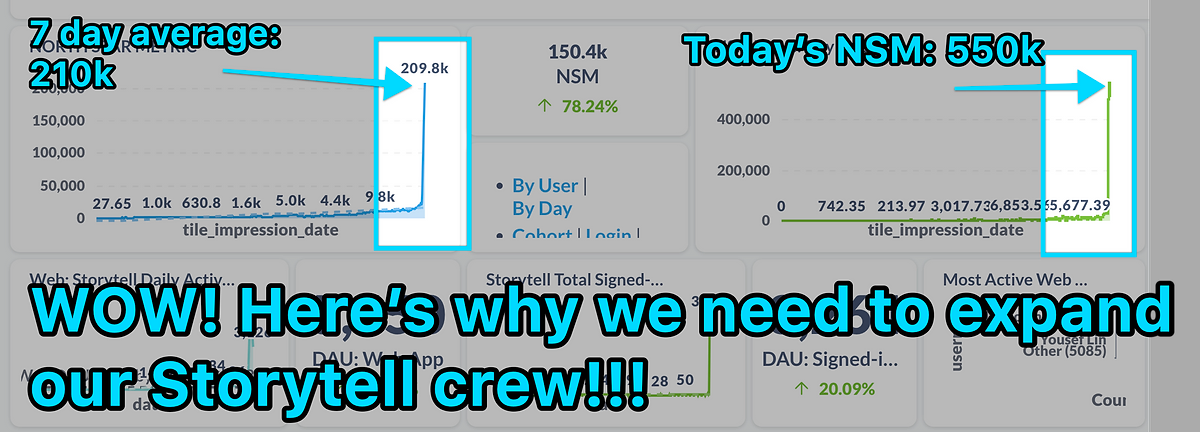
By early December, our NSM was close to 20,000. Previously, our growth was entirely organic. By this time, we felt we could start to do a bit of growth hacking. In December, we started some influencer marketing activities, and our NSM grew by 30 times, reaching 550K!
From an NSM of less than 1 at the beginning of the year to 550K by the end of the year, in 2023 we turned Storytell from a demo into a product with a loyal user base. I am proud of our Crew and very grateful to our early users and design partners.
Words at the end
From a young age, I have been particularly fond of reading books on the history of entrepreneurship. The year 2023 marks the beginning of a new era for me to embark this journey. I know the road ahead is challenging, but I am fortunate to experience this process firsthand with my two amazing partners and our Crew. Regardless of the outcome, I will forge ahead with all the Storytell Crew, fearless and without regret. Looking forward to Storytell riding the waves in 2024!
Also, Storytell.ai is hiring front-end and full-stack engineers: https://go.storytell.ai/fse-role. If you are interested or you know anyone might be interested, please don’t hesitate to contact me at my email jingconan@storytell.ai.
在我思考的过程中,我逐渐接触到Software as a Service (SaaS)的商业模式,觉得这才是大模型的正确商业模式。在SaaS里面,只有切实的为用户提供持续的价值,用户才会付费订阅。SaaS讲究的是客户驱动,而谷歌的文化过分强调工程师文化,忽略了客户价值。这使得在谷歌内部探索这个道路非常困难。最终我坚定了离开谷歌,决定做一个自己SaaS的创业公司。我在2019年底加入了一家SaaS初创公司成为Founding Member,了解了SaaS公司从0到1的构建过程。在这个过程中也同时寻找合适的商业合伙人。终于在2022年我和两个合伙人创立了Storytell.ai。
我们在2022年12月份开始开发Chrome插件。我们考虑这个主要解决上面这些问题。Chrome插件虽然也有Friction,但是用户可以选择个人安装。Chrome插件也可以自动summarize用户访问过的页面(实现AI as a companion的效果)。另外Chrome 插件比较容易形成个人和工作的协同。在Chrome Extension的迭代过程中,我们意识到Chat是一种最为重要的交互手段。用户通过提问(或者提示词prompt)可以将准确的表达他们的需求。我们虽然在Slack阶段也允许用户提问,但是主要的重心还是放在提供一系列的按钮。在Chrome Extension的迭代过程中,我们发现了聊天的的界面具有很大的灵活性,并且可以快速的发现没有预先定义好的客户需求。
我们在创立之初第一件事情就是厘清公司的愿景和文化。企业的愿景和文化真正定义了一个企业的基因,愿景是帮助我们知道该向何处去,文化保证我们有效的合作。Storytell的愿景是希望能够成为(Clarity Layer),利用AI来帮助人从纷繁的信息里面抽丝剥茧(https://go.storytell.ai/vision)。我们有了六个企业文化价值:1)杠杆思维 Apply High-Leverage Thinking。2)同舟共济 Everyone is Crew。 3)市场驱动 Market Signal is our North Star。 4)默认透明。We Default to Transparency。 5)坦诚沟通 We Prioritize Courageous Candor in our Interactions。 感兴趣的朋友可以看这里 https://go.Storytell.ai/values。我们在公司创建的过程中也特别注重团队文化建设。我们从开始希望的是work hard but also play harder。每一个季度我们都会有offsite。整个团队都非常喜欢户外和Camping,所以我们经常举行各种户外活动(我们有一个共享相册,有我们成立第一天开始的照片)。我们称自己为Storytell Crew。就是希望我们能够向一个宇航员机组一样,一起跨越星辰大海。
Last week, an intriguing discussion caught my attention at a fantastic event organized by Leni. The panel discussion revolved around an interesting comparison: Will the Generative AI industry resemble the Coffee industry, with a dominant player like Starbucks, or the Winery industry, characterized by a multitude of providers offering differentiated products?
This thought-provoking question led me to delve deeper into the dynamics of the Generative AI industry. Here are my thoughts.
In any industry, two key factors significantly influence its structure – the fixed and marginal costs of producing the product and the price for each unit of service. Let’s consider the Coffee and Winery industries for context.
In the Coffee industry, the high fixed cost – primarily branding – incentivizes scaling. Starbucks, for instance, has invested heavily in establishing a formidable brand and hence, scales up to distribute the cost. On the contrary, the Winery industry thrives on differentiation, with numerous wineries offering unique products.
Now, let’s apply these factors to the Generative AI industry. The industry can be divided into three essential layers as per the framework described by A16z:
1) The Infrastructure layer, which runs training and inference workloads for generative AI models.
2) The Foundational Model Layer, which provides the Foundational model via a proprietary API or open-source model checkpoints.
3) The Application Layer, where companies transform generative AI models into user-facing products, either by running their own model pipelines (“end-to-end apps”) or relying on a third-party API.
For the Foundational Model vendors, there’s a high fixed cost involved in training the models, and the marginal cost of providing a unit of service (API call) is quite low. Moreover, most sales are made through API calls, which have a low unit sale price. This dynamic, coupled with the fierce competition and the rise of competitive open-source alternatives, is causing the pricing power of Proprietary API vendors to shrink rapidly. As a result, the Foundational Model market is likely to resemble the Coffee industry, where you either go to Starbucks (OpenAI), or you make your own coffee (Open Source). Infrastructure layer has very similar dynamics as the Foundational Model layer so I will skip it in this discussion.
Moving to the Application Layer, it’s essential to differentiate between consumer and enterprise applications. Consumer applications are likely to follow the Coffee industry’s pattern due to the significant fixed cost of creating a consumer-facing brand and the strong incentive to scale.
However, enterprise applications might mirror the Winery industry. With the wide availability of LLM APIs, creating an enterprise AI application no longer requires a substantial fixed cost. Although there are some fixed costs required for enterprises (e.g., data compliance), they are not on the same level as training LLM and can be sequenced in the iteration with customers. Moreover, the price for enterprise applications can be quite high (up to 6 or 7-figure for a single account), fostering an expectation for differentiated services.
In conclusion, the Generative AI industry presents a unique blend of the Coffee and Winery industries’ dynamics. The Foundational Model Layer and consumer applications at the Application Layer are akin to the Coffee industry, while enterprise applications at the Application Layer resemble the Winery industry. As the industry evolves, it will be fascinating to see how these dynamics play out.
This blog is finished with the help of SmartChat™ by Storytell.ai (both in the stage of researching content and rewriting the final draft). It is available for initial testing. Please sign in at storytell.ai and click dashboard like this https://share.getcloudapp.com/nOuLGPGN to access this feature.
I grew up in a very risk-reverse family. Although my parents’ home was only 0.5 miles away from many beautiful lakes, I was never allowed to swim because my parents were worried that I would be drowned. Not wanting to worry my parents, I always followed a safe path in my life. Staying safe became my habit — a regretful one.
I have wanted to be an entrepreneur since 15. However, it took me another 17 years before I took the plunge. I used to think that it was the lack of technology skills that prevented me from being an entrepreneur.
However, even after I worked my way up to Google Brain, one of the most renowned tech innovation labs, I was still unable to make up my mind to be an entrepreneur. I was frustrated, distraught, and unsatisfied.
Fortunately, I eventually found my way thanks to a pivotal moment in my life. In Nov 2021, my little Angel Adalyn was born and gave me a whole new perspective on life. I was in the same position with my parents 30 years earlier — Do I want Adalyn to be safe for me, or be herself?
I didn’t want to make a decision for her. I wanted to show her how I would do for myself.
I am also so grateful to meet DROdio who showed me how to be an adventure dad. I started by stocking up camping gears and did long road trip with my SUV. Eventually, I became a #Vanlifer and a proud owner of Winnebago.
Jing is with his families in their first trip in their Winnebago Van
Both being a Dad and being a vanlifer changed my perspective. I started to embrace adventure and explore new worlds in my life.
Eventually, it led to a wonderful new adventure to build Storytell.ai with two amazing partners DROdio and Erika. We had so much fun together to bring Storytell.ai from an idea to where we are.
Jing, DROdio, and Erika in a Halloween Party organized by an investor
We also build our venture as an adventure.
DROdio’s (Right) and Jing’s van (left) parked in the Storytell.ai’s Tahoe Offsite (Dec 2022)
Jing was working at a Catamaran for our Storytell advisor & user offsite at BVI. Thanks Elon! (June 2023)
Jing and Storytell advisor Asa and user Phin sailed at BVI. Jing and Phin also shipped an MVP on the ship.
We are still small, but we are fearless. There is always ups-and-downs in startup building, but there is also so much fun of experiencing adventure together with a group of like-minded friends.
I am proud to be be an adventure Dad and adventure CTO.
If I ever build a time machine to tell younger myself one tip. I will say to him: Be yourself, be adventurous.
We are currently in the midst of a boom era for Generative AI, and the landscape is changing almost daily. For more details, please refer to this blog post. The possibilities seem endless!
However, this is also an increasingly confusing time for builders. After spending months fine-tuning GPT-3, you may wake up to find that the model is now irrelevant due to the availability of GPT-4. Similarly, while working on building your workflow, you may discover that AutoGPT has taken over your niche.
In this fast-changing era, it’s crucial to build a solid foundation that allows you to leverage the benefits of the generative AI revolution.
FAST Framework
We introduce the FAST Framework for describing the characteristics of a tech team suitable for building a generative AI product. The FAST Framework consists of four elements:
Flexibility: To support product pivots without wasting a lot of work.
Accuracy: To ensure that AI generates valuable results for users.
Scalability: To enable a good user experience at a large scale and cost-effectively.
Tight-knit development workflow: To allow the team to build products with user feedback in a high-velocity manner.
How Storytell Plans to build our Technology Foundations
Let me explain how Storytell plans to incorporate the framework. To begin, let me describe the Storytell system at a high level. Our technology stack primarily consists of three systems:
The front-end system, which includes anything related to user interface and user interaction.
The back-end system, which handles data processing.
The AI system, which is our core algorithm for distilling signal from noise.
Flexibility
For the front-end system, one of the key challenges is to be flexible enough to adapt to different distribution channels such as the Chrome Web Store, Apple App Store, websites, and Slack App. Each channel has its own front-end UI development guideline. However, as the current AI era represents a paradigm shift, it is unclear which channel will eventually emerge as the winner. Therefore, it is essential to be able to experiment quickly at this stage. This often means revamping the front-end UI every few months. It would be a huge waste of effort if a team had to start from scratch each time they need to prioritize a new distribution channel.
The critical challenge for AI systems is to design an architecture that is agnostic to changes in the generative AI platform. For an overview of the generative AI platform, please see this A16z blog.
Accuracy
Accuracy has been a major issue for Large Language Models (LLMs), which are the workhorses of generative AI. LLMs from Google, OpenAI, and Microsoft all suffer from “hallucinations,” in which the AI confidently generates fake statements. Accuracy is a significant obstacle to applying LLMs to high-value use cases, such as enterprise applications. Any company working in the generative AI field must have a systematic way to improve accuracy of their AI system.
Two capabilities are required to address accuracy problems.
Fast user feedback and adaptive learning. Users should have the ability to report inaccuracies, and the system should be able to quickly adapt to feedback.
System to Ensure Accuracy: An AI system should adhere to certain rules or guarantees. One important rule is that the output should never be inappropriate. Additionally, due to the probabilistic nature of LLMs, it is necessary to build a software stack on top of them to ensure accuracy.
Scalability
Generative AI can be both expensive and slow. While APIs like OpenAI and open source models like LLaMA have made it easier to build generative AI systems, it remains challenging to build a scalable back-end system. The fast-changing landscape of generative AI makes this particularly difficult.
If you choose to use an API, the latency is often very high. Therefore, you need to design a system that can accommodate this latency. On the other hand, if you choose to use open-source models, the accuracy is likely to be worse. In this case, you need to design a system that can improve accuracy, for example, by using certain types of fine-tuning. Additionally, you need to design your system to tune efficiently because the base models change very rapidly.
Many API and open-source models have limits on the maximum amount of text you can send to the API, known as the token limit. To ensure that your system works within this limit and does not negatively impact your model’s performance, you need to design it accordingly.
Many API providers specify a maximum quota for API calls. You will need to work within this requirement by minimizing the number of API calls made.
Tight-knit development workflow
The typical product development cycle involves the following steps: user feedback collection -> feature prioritization -> development -> feature impact analysis. It is crucial to accelerate this cycle and make it as continuous as possible.
When collecting user feedback, you may have a separate customer team responsible for its collection. However, it is crucial for your engineers to also listen to user feedback. This requires having a development team that is highly focused on the needs of users.
Having a systematic way to identify important features that will benefit the business is crucial for feature prioritization. It’s essential to align the entire team with a single metric, known as the north-star metric. Prioritization should be done on a daily basis, rather than quarterly.
For software development, it is essential to be able to ship code as quickly as possible. Both technology capabilities and market needs are evolving rapidly. To find a product-market fit, you need to move faster than both. This means you need to be able to ship code continuously. Investment in software development lifecycle (SDLC) tools and continuous integration/continuous delivery (CI/CD) systems is crucial.
For feature impact analysis, it is important to collect user data as early as possible. This allows you to analyze user patterns and identify the top use cases. It is also worthwhile to invest in the business intelligence stack early on.
We are currently hiring for our Backend/ML role. If Storytell’s vision resonates with you and you want to help build it, please email me at jingconan@storytell.ai. For more information, please visit our career page and vision statement.
How has economic evolution changed the way birthday cakes are made? In their classical Harvard business review article, Joseph Pine IIand James H. Gilmore asked this question and gave their answer:
In an agrarian economy, parents make birthday cakes by themselves.
In an industrial economy, parents purchase premixed ingredients from the market.
In a service economy, parents order cakes as a yearly service for their kids.
In an experience economy, there will be “experience vendors” who could create an awesome birthday party for kids.
Their framework is also applicable to software.
Agrarian economy: every business needs to write software for their use cases.
Industrial economy: there are software vendors dedicated to building software, which could be purchased by customers to solve their needs.
Service Economy: The software is delivered as a service (often as a subscription) and it would still require customers to build upon the service to create an awesome experience. This is the Software-as-a-Service (SaaS) model.
Experience Economy: We are entering a new era of Software-as-a-Experience (SaaE). In the SaaE model, we use software to directly orchestrate experiences for our users. Software is not considered only a utility, but a conduit of digital experiences.
SaaE is a fundamental leap forward for the SaaS business model because it significantly reduces the friction for creating awesome user experiences. According to Joseph and James,
an experience occurs when a company intentionally uses services as the stage, and goods as props, to engage individual customers in a way that creates a memorable event. … No two people can have the same experience, because each experience derives from the interaction between the staged event (like a theatrical play) and the individual’s state of mind.
In the SaaS model, the software service itself is rigid. There is a predetermined way, often determined during the product build stage, to use the software. Users would continue their subscription only if the problem they face could be solved by the predetermined software flow. When this is no longer the case, customers would churn.
In the SaaE model, the software would be adaptive rather than rigid. The ultimate goal is to deliver the best experience to users by staging a sequence of software services intentionally.
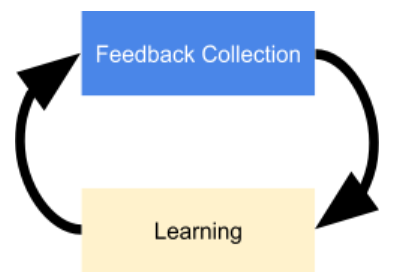
To reach the goal, we need two new software layers:
A feedback-collection layer that could continually integrate the feedback from each customer to the product.
A learning layer for software behaviors to adjust the software services to deliver the best customer experience.
Figure: Two layers of the SaaE.
The two layers were not practical in the software building process before because it would take an enormous amount of effort to personalize the software flow for each user.
The advancement of AI has made personalizing unique experiences for each user possible. We have already done it — YouTube’s personalized feed creates a unique video watching experience for every user, and Amazon’s product recommendation has created a unique purchase experience for every customer.
Those systems are currently referred to as recommendation systems. But this is just the tip of the iceberg for a large paradigm shift – the advent of the “Software-as-a-Experience” age.
Morris Chang may not be a household name in the western world but his achievement is comparable to that of western business Titans like Rockefeller and Carnegie. His life consists of one miracle by another. After fleeing from China to the US during the China Civil War, he worked his way up to be the general manager of the Semiconductor businesses and 3rd ranked person of Texas Instrument — one of the biggest semiconductors companies in the world. Chang was one of the first Chinese Americans to become top business leaders. In his 50s, he returned to Taiwan and founded Taiwan Semiconductor Manufacturing Company (TMSC) and became the “godfather” of Taiwan’s semiconductor industry.
Chang was born in China in 1931. Most of his early life was deeply shaped by war — he was forced to flee three times due to the Second Sino-Japanese war and China civil war. After the wars, he came to the United States at the age of 17 to study at Harvard University, a school that primarily focused on arts and humanities education. As an underrepresented minority ethnic group, most Chinese Americans at the time worked in low-end restaurants or laundry businesses. Academic jobs were the only few alternative options that would fit with Chang’s mission of achieving big societal impacts. He later transferred to MIT in the hope of becoming a scholar in engineering majors. Unfortunately, he failed the qualifying exams twice at MIT and had to quit his academic path and went to the job market after obtaining his master’s degree.
He entered the Semiconductor industry in his first job at Sylvania, an industry leader then. However, his team was dismantled three years later. He then moved to Texas Instrument, which was famous for the invention of integrated circuits (IC) and was fast-growing. After working at Texas Instrument for three years, he went back to Stanford to pursue a Ph.D. degree and then returned to Texas Instrument to continue his corporate duty. By the 1970s, Chang was already the general manager of the whole semiconductor business of Texas Instrument.
Chang was a keen observer of the semiconductor industry. While working at Texas Instrument, he observed that a lot of brilliant people in the company were hoping to create new businesses but heavy investment requirements prevented them from getting started. As chips became more and more sophisticated, the chip manufacturing business became super capital-intensive. The cost of creating a chip manufacturing line (also known as “foundry” or “fab”) could easily be over 3-4 billion US dollars. Besides, new startups cannot maintain a sustainable stream of needs to keep their manufacturing line busy all the time, which is the only way to justify the heavy investments.
In contrast, chip designing requires much less capital. It would be a win-win situation if there is a “pure-play” company that focuses on manufacturing so that startups could focus on designing. This model of chip making process, also known as Fabless manufacturing as it features the split of designing and manufacturing, is crucial for the booming of the semiconductor industry. There were a lot of chip design talents in the US, but very few were good at both chip manufacturing and cost management. Chang was one of the few talents who had the expertise.
Chang started to face career setbacks in the early 1980s. At the time, Texas Instrument shifted focus away from semiconductors and became a diversified device manufacturer. Chang disagreed with the shift and had to leave the company. After the career setback, Change decided to turn his observation into action. At the same time, Taiwan government was eager to find ways to break into high-end industries like chip manufacturing. Chang was the perfect person to lead the cause. After a short stint at another company, Chang accepted the invitation from the Taiwan government to be the first chairman of the Industrial Technology Research Institute, an institute that played a critical role in the industrial transformation of the island. With the support of the Taiwan government, Chang founded the TSMC one year later. TSMC created a whole new industry of “pure-play” chip manufacturing (a.k.a., foundry industry). By focusing on only manufacturing but not designing, TSMC assured its partners, typically US chip designing firms, that TSMC won’t compete with them or share their trade secrets with their competitors.
Now TSMC is undoubtedly the market leader in the industry and occupies 28% of the market share in a recent study. Also thanks to TSMC, Taiwan became crucial for the global semiconductor supply chain, which Bloomberg has recently published an article to illustrate.
Global semiconductor market share (image via Counterpoints Research)
In one of his recent talks, Chang gave a summary of what he thinks is the key reason for the TMSC’s success. Chang attributed the success to three factors.
The number one is Taiwanese people’s hard-working spirit. For example, during his second stint at TMSC, Chang started the “nightingale program”, which included both day and night shifts to ensure there were R&D activities 24/7. This program would be unimaginable in U.S. companies. According to Chang, this nightingale program was the key reason why the TSMC could eclipse all of its competitors in technology. In chip manufacturing, the size of the device the manufacturing process could produce is a key indicator of technology level — smaller size means more devices in the same area but also is much harder to manufacture. After losing in the competition of the 14nm manufacturing process, TSMC reached the 10nm, 7nm, and 5nm manufacturing processes one by one in just a few years. Till now, none of its competitors have reached the 10nm milestone yet. Please refer to RISC-V, China, Nightingales for more details.
Figure. The timeline of manufacturing process in major foundry companies.
The second factor is the local professional management. This factor is crucial because chip manufacturing is operation-heavy and efficiency-driven. Chang also mentioned that managerial talent doesn’t transfer well across borders because of culture and factors.
The third factor is the good infrastructure provided by the Taiwan government. It is easy to see how good infrastructure makes the transportation of goods much easier. Chang also mentioned an important point. The good high-speed railway and the small Island of Taiwan make it possible for talents to be relocated to any place within the island without the need to be separated from their families. The benefits of good infrastructure on the human management side are often ignored by governments but are crucial for businesses that require a lot of talent.
All the three points are about one thing: TSMC can attract a huge amount of disciplined and high-quality talent and can retain them through good management and providing a convenient life. The company has an envious 3-4% employee turnover rate. For those who leave for various reasons, they became the most sought-after talents in the industry. I also highly recommend this great essay by Kevin Xu based on Chang’s talk.
Throughout his life, Chang overcame one challenge by another and successfully turned setbacks into new opportunities. Although he became a refugee three times in his youth, he immigrated to the US to pursue a new life. After failing in MIT Ph.D. qualifying exams and crumbling his academic pursuit, Chang entered the newborn semiconductor industry and worked tirelessly to become an expert in semiconductor manufacturing. After facing a career setback in Texas Instrument, he took the courage to leave the US, a place he had spent 36 years, to Taiwan for creating TSMC and became the godfather of the semiconductor industry of the Island.
Chang is also a great writer. I highly recommend his Chinese autobiography that covered his early life before 33 years old (unfortunately I haven’t found any translated version yet). Besides, he is working on the second half of this auto-biography, and hopefully, will publish it soon. I am very much looking forward to reading it and will share a sequel in the future.